- · 模式识别与人工智能版面[04/29]
- · 《模式识别与人工智能》[04/29]
- · 《模式识别与人工智能》[04/29]
- · 《模式识别与人工智能》[04/29]
一、本刊要求作者有严谨的学风和朴实的文风,提倡互相尊重和自由讨论。凡采用他人学说,必须加注说明。 二、不要超过10000字为宜,精粹的短篇,尤为欢迎。 三、请作者将稿件(用WORD格式)发送到下面给出的征文信箱中。 四、凡来稿请作者自留底稿,恕不退稿。 五、为规范排版,请作者在上传修改稿时严格按以下要求: 1.论文要求有题名、摘要、关键词、作者姓名、作者工作单位(名称,省市邮编)等内容一份。 2.基金项目和作者简介按下列格式: 基金项目:项目名称(编号) 作者简介:姓名(出生年-),性别,民族(汉族可省略),籍贯,职称,学位,研究方向。 3.文章一般有引言部分和正文部分,正文部分用阿拉伯数字分级编号法,一般用两级。插图下方应注明图序和图名。表格应采用三线表,表格上方应注明表序和表名。 4.参考文献列出的一般应限于作者直接阅读过的、最主要的、发表在正式出版物上的文献。其他相关注释可用脚注在当页标注。参考文献的著录应执行国家标准GB7714-87的规定,采用顺序编码制。
预训练大模型产业落地的爆发前夜,这家企业走
作者:网站采编关键词:
摘要:2021年是大规模预训练模型的爆发之年,掀起了人工智能又一波热潮,并迅速成为AI领域的技术新高地,助推人工智能从1.0的感知智能向2.0的认知智能转变。 自从2012年深度学习的应用元
2021年是大规模预训练模型的爆发之年,掀起了人工智能又一波热潮,并迅速成为AI领域的技术新高地,助推人工智能从1.0的感知智能向2.0的认知智能转变。
自从2012年深度学习的应用元年以来,人脸识别、语音识别等技术通过机器学习实现了大量应用场景突破,不仅提升了社会工作效率,同时改变了人们的生活出行模式,建立了人类对人工智能技术的基础认知。但是经过多年的应用实践,传统人工智能基于特定场景、特定内容、特定需求的适配模式也暴露出很多短板,尤其在泛场景应用、小样本及复杂场景上,只能达到“有多少人工,就有多少智能”的基础感知,识别准确度差,泛化能力低。要实现人工智能的真正落地,必须让机器具备通识知识的自学习能力,以及对业务的逻辑判断能力,建立机器综合认知体系。工欲善其事必先利其器,预训练技术让深度神经网络模型可以对大规模无标注数据进行自监督学习,使超大规模模型的建立成为可能。自从2018年Google推出BERT以来,Open AI、Google、Facebook、Microsoft、英伟达、智源研究院、阿里达摩院、华为、百度等研发机构和企业纷纷进行大规模预训练模型布局,掀起了一轮拼参数、拼算力的AI军备竞赛。虽然这轮竞赛参数规模呈指数级增长,但技术应用各有侧重。于是2021年8月,基于各类大模型的特性和未来发展前景,斯坦福大学的Percy Liang、李飞飞等100多位学者联名发表了一份 200 多页的重磅研究综述《On the Opportunities and Risk of Foundation Models》,将大规模预训练模型统一命名为基础模型(Foundation Models),并从基础模型的能力、应用领域、技术层面和社会影响等四个方面阐述了基础模型面临的机遇和挑战,奠定了大规模预训练模型的理论基础,也正式标志着人工智能2.0序幕的正式拉开。在新一轮大规模预训练模型的商业化热潮中,近期,由深投控领投,融创投资等共同参与的联汇科技D轮融资,使这家从事大规模预训练模型研发的新型AI公司浮出水面。不同于大量的AI新创企业,联汇科技拥有十多年的行业积累,以及对音视图文处理分析技术的丰富应用经验,正如一只等风来的候鸟,积极打造针对视觉语言的多模态预训练大模型,努力改变视觉分析和多模态分析领域的人工智能技术实现方式。
 联汇科技的首席科学家赵天成博士是一位世界级的AI青年科学家,毕业于全球计算机领域顶级院校—卡耐基梅隆大学,获得计算机博士学位,在多模态机器学习和自然语言处理领域属国际青年创新型人才,是端到端人机交互理论的开创者,受到Google、微软、亚马逊等同行顶级专家的高度评价,曾多次担任国际顶尖会议和期刊的审稿人和区域主席,在国际顶级会议和期刊上发表论文30余篇,多次获得最佳论文奖,并且2018年获得微软研究院Best & Brightest PhD荣誉。
联汇科技的首席科学家赵天成博士是一位世界级的AI青年科学家,毕业于全球计算机领域顶级院校—卡耐基梅隆大学,获得计算机博士学位,在多模态机器学习和自然语言处理领域属国际青年创新型人才,是端到端人机交互理论的开创者,受到Google、微软、亚马逊等同行顶级专家的高度评价,曾多次担任国际顶尖会议和期刊的审稿人和区域主席,在国际顶级会议和期刊上发表论文30余篇,多次获得最佳论文奖,并且2018年获得微软研究院Best & Brightest PhD荣誉。
赵天成博士一直以来专注于提高机器认知能力的研究,让机器可以理解更多模态的数据类型,能像人脑一样用更少的数据样本自主学习和理解更加复杂的知识。基于在卡内基梅隆大学的长期研究,赵天成博士带领团队创建了拥有自主知识产权的视觉语言大规模预训练模型OmModel。不同于国内大部分研发机构和企业聚焦在较为成熟的大规模语言模型,联汇科技聚焦在更为前沿的视觉语言大模型赛道。所谓视觉语言模型,也就是通过一个预训练模型同时理解自然语言和视觉信息,并且可以构建他们之间的关系。因此相较于只能解决NLP问题的语言模型,视觉语言模型的应用面更广、可以解决更加复杂的实际问题,通过联系视觉和语言这两大重要的模态信息,让人工智能真正拥有认知能力。目前联汇科技的OmModel已经完成了基于超过数十亿字符、近十亿图片和视频数据的大规模预训练,同时在包括目标检测、行为识别、跨模态检索等多项重要任务上展现出超强的零样本泛化能力和小样本学习能力。
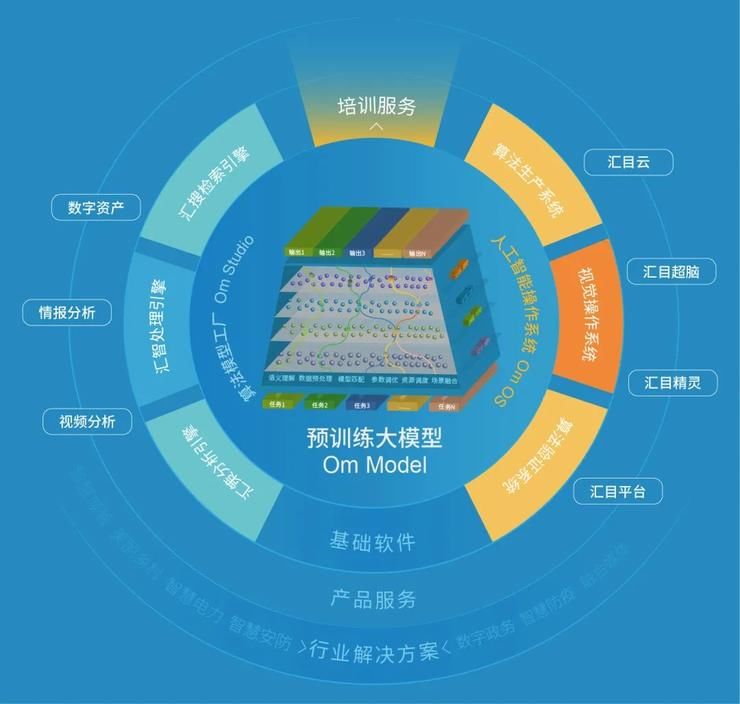
此外,回归商业本质,强调核心技术的商业化落地也是联汇科技的一大特色。“我们的目标是打造行业大模型系统,让预训练大模型真正实现产业化落地,变成对客户有价值的产品,而不是单纯地追求模型的参数量。”赵天成博士表示。
目前,联汇科技正在基于OmModel从底层构建全新的基于预训练大模型的人工智能操作系统(Om OS)和模型算法工厂(Om Studio),提供一站式AI视觉应用服务。Om Studio让用户可以在没有训练数据或者极少训练数据的前提下,利用大模型的超强通识能力,在几个小时内完成AI视觉算法适配,实现AI业务应用零门槛上手,服务千行百业的视觉场景应用。针对少量特定需求任务,OmModel只需较少样本的标注数据进行微调即可实现应用适配。改变了传统人工智能需要大量高级工程师和海量标注数据的困境,大幅度降低了人工智能应用构建的门槛,同时提高了响应效率,实现人工智能2.0向大量长尾泛需求的扩展。而Om OS是大模型的运行和操作系统,让用户可结合语义进行基础的逻辑判断,实现业务知识和AI模型的有效结合,真正解决需求方的痛点。比如针对车站等复杂场景戴口罩场景的识别判断,不仅可以判断是否戴口罩,还可以判断出口罩佩戴是否规范、排除儿童未戴口罩、排除在饮用食物未戴口罩等行为,而这一切不需要依赖样本数据训练,只需要通过简单语义定义即可。通过这一系列的创新技术应用,使得OmModel视觉语言大规模预训练模型在自主学习能力、响应能力、认知识别能力上得到了质的提升。目前联汇科技的Om OS和Om Studio两大产品已经实现基于多模态数据文件的数字资产管理、知识图谱分析等应用,以及基于监控摄像机信号的美丽乡村、智慧城管、数字防疫、智慧门店、明厨亮灶数十个场景的应用落地。并率先在国内开启人工智能从感知智能向认知智能转变的2.0迭代升级,打破了传统人工智能对样本数据的依赖,实现仅用10%的标注数据快速解决传统算法厂商无法应对的80%的长尾应用场景,极大地降低了人工智能的落地应用门槛,有利于快速、低成本地普及视觉认知技术在各行业的应用,为百行千业的数字化改革提供技术赋能。联汇科技通过大规模预训练模型在人工智能业务应用上的实践,证明人工智能从感知智能向认知智能转变的可能,大规模预训练模型势必带来人工智能技术的二次碰撞。碰撞即是融合,历史的车轮总是在碰撞中前进,人工智能技术前进的车轮亦是如此,人类畅想未来的步伐未曾停步。
文章来源:《模式识别与人工智能》 网址: http://www.mssbyrgznqks.cn/zonghexinwen/2022/0422/808.html